En este método el sistema operativo sólo tiene que guardar en qué orden las páginas fueron cargadas, de modo que al necesitar hacer espacio pueda fácilmente elegir la primera página cargada. Se usa una cola, al cargar una página nueva se ingresa en el último lugar. Aunque las colas FIFO son simples e intuitivas, no se comportan de manera aceptable en la aplicación práctica, por lo que es raro su uso en su forma simple. Uno de los problemas que presentan es la llamada Anomalía FIFO o Anomalía de Belady. Belady encontró ejemplos en los que un sistema con un número de marcos de páginas igual a tres tenía menos fallos de páginas que un sistema con cuatro marcos de páginas. El problema consiste en que podemos quitar de memoria una página de memoria muy usada, sólo porque es la más antigua.
Mes: May 2017
No usada recientemente (Not Recently Used, NRU)
Este algoritmo favorece a las páginas que fueron usadas recientemente. Funciona de la siguiente manera: cuando una página es referenciada, fija el bit de referencia para esa página. Similarmente, cuando una página es modificada, fija su bit de modificación. Usualmente estas operaciones son realizadas por el hardware, aunque puede hacerse también por software. En un tiempo fijo, el sistema operativo pone en 0 los bits de referencia de todas las páginas, de modo que las páginas con su bit de referencia en 1 son las que fueron referenciadas dentro del último intervalo de reloj. Cuando una página debe ser reemplazada, el sistema operativo divide las páginas en cuatro categorías:
- Categoría 1: no referenciada, no modificada
- Categoría 2: no referenciada, modificada (Categoría sin lógica alguna)
- Categoría 3: referenciada, no modificada
- Categoría 4: referenciada, modificada
Las mejores páginas para cambiar son las que se encuentran en la categoría 0, mientras que las peores son las de la categoría 3. Se desaloja al azar una página de la categoría más baja que no esté vacía. Este algoritmo se basa en la suposición de que es mejor desalojar una página modificada a la que no se ha hecho referencia en al menos un tic de reloj, en vez de una página limpia que se está usando mucho.
Rendimiento en Paginación por Demanda con Intercambio
Tasa de fallo de pagina 0<= p<= 1.0
si p=0 no hay fallo de pagina
si p=1 cada referencia es un fallo de pagina
Tiempo de acceso efectivo con intercambio= EATS
EATS= (1-p)* acceso a memoria+p*(sobrecarga de fallo de pagina+ [descarga]+carga+reinicio)
EATS= (1-p)*t+p*f
- El tiempo que importa es el de carga de memoria de intercambio a memoria real.
Ejemplo rendimiento en paginacion por demanda con intercambio
EATS=(1-p)*t+p*f
Si suponemos un t=100ns y un disco con latencia = 8ms, t.busqueda = 15ms y t.transferencia=1ms, tendramos un tiempo promedio de fallo f= ms
EATS=(1-p)*100+p*(25.000.000)
100+24.999,900*p (en ns)
Lo cual significa que el tiempo de acceso está muy relacionado con la tasa de fallos de paginacion.(en general t<<f)
Buffer de Traducción Anticipada o TLB
De nuevo el principio de localidad: Si las referencias tienen localidad entonces la traducción de direcciones también debe tener localidad.
- El buffer de traducción anticipada (translation-lookaside buffer) o TLB es una cache, habitualmente totalmente asociativa o asociativa por conjuntos, cuyas entradas contienen: en la parte de la etiqueta, el número de página virtual (o parte) y en la parte del dato, el número de página física y los bits de control.
- Un tamaño de página mayor hace que más memoria pueda estar mapeada con una entrada, por lo que se reduce el número de fallos en la TLB.
- Hay TLBs unificadas y separadas (datos e instrucciones).
- Cuando se combinan caches y memoria virtual, la dirección virtual debe ser traducida a una dirección física mediante la TLB antes de que pueda acceder a la cache (elevado tiempo de acierto).
- Una forma de reducir el tiempo de acierto es:
- Acceder a la cache únicamente con el desplazamiento de página (no necesita ser traducido) y mientras se están leyendo las etiquetas de dirección de la cache, el número de página virtual es enviado a la TLB para ser traducido.
- Como la TLB es habitualmente más pequeña y rápida que la memoria de etiquetas de la cache, la lectura de la TLB puede hacerse de forma simultánea a la lectura de la memoria de etiquetas sin ralentizar los tiempos de acierto de la cache después la comparación de direcciones se realiza entre la dirección física de la TLB y la etiqueta de la cache.
- Inconveniente: una cache de correspondencia directa no puede ser mayor que una página.
- Otra alternativa es utilizar caches virtuales.
Desventajas de un Sistema con Segmentación Paginada
Por otro lado, este esquema tiene sus desventajas, las cuales son:
- Las tres componentes de la dirección y el proceso de formación de direcciones hacen que se incremente el costo de su implementación. El costo es mayor que en el caso de segmentación pura o paginación pura.
- Se hace necesario mantener un número mayor de tablas en memoria, lo que implica un mayor costo de almacenamiento.
- Sigue existiendo el problema de fragmentación interna de todas o casi todas las páginas finales de cada uno de los segmentos. Bajo paginación pura se desperdician solo la última página asignada, mientras que bajo segmentación paginada el desperdicio puede ocurrir en todos los segmentos asignados.
Ventajas de un Sistema con Segmentación Paginada
El esquema de segmentación paginada tiene todas las ventajas de la segmentación y la paginación:
- Se garantiza la facilidad de implantar la compartición y enlaces.
- Se simplifican las estrategias de almacenamiento.
- Se elimina el problema de la fragmentación externa y la necesidad de compactación.
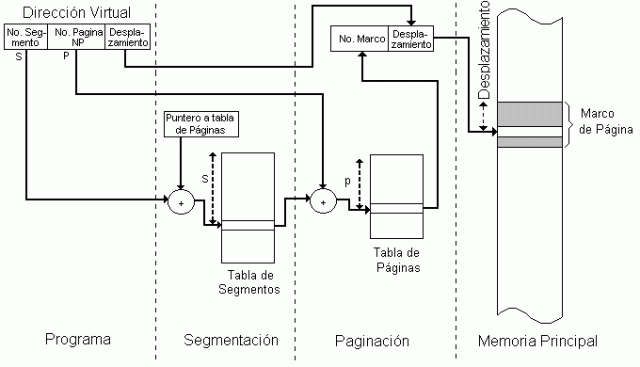
Segmentación Paginada
Esta técnica permite minimizar las desventajas mencionadas anteriormente. Combinando los esquemas de paginación y segmentación.
Para la segmentación se necesita que estén cargadas en memoria, áreas de tamaños variables. Si se requiere cargar un segmento en memoria; que antes estuvo en ella y fue removido a memoria secundaria; se necesita encontrar una región de la memoria lo suficientemente grande para contenerlo, lo cual no es siempre factible; en cambio “recargar” una página implica solo encontrar un marco de página disponible.
A nivel de paginación, si se desea referenciar en forma cíclicas n páginas , estas deberán ser cargadas una a una generándose varias interrupciones por fallas de páginas ; bajo segmentación, esta página podría conformar un solo segmento, generando una sola interrupción, por falla de segmento. No obstante, si bajo segmentación, se desea acceder a un área muy pequeña dentro de un segmento muy grande, este deberá cargarse completamente en memoria, desperdiciándose memoria; bajo paginación solo se cargará la página que contiene los ítems referenciados.
Puede hacerse una combinación de segmentación y paginación para obtener las ventajas de ambas. En lugar de tratar un segmento como una unidad contigua, este puede dividirse en páginas. Cada segmento puede ser descrito por su propia tabla de páginas.
Los segmentos son usualmente múltiplos de páginas en tamaño, y no es necesario que todas las páginas se encuentren en memoria principal a la vez; además las páginas de un mismo segmento, aunque se encuentren contiguas en memoria virtual, no necesitan estarlo en memoria real.
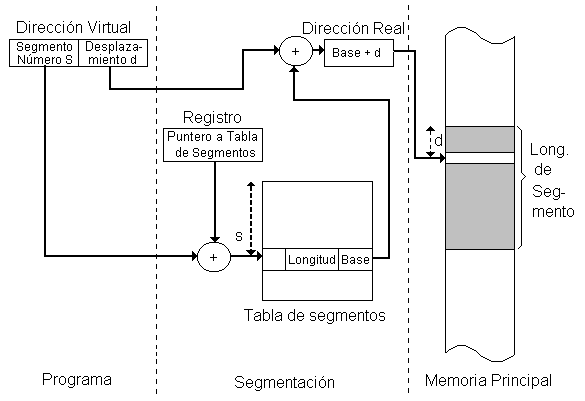
Las direcciones tienen tres componentes: (s, p, d), donde:
s =número del segmento,
p = número de la página dentro del segmento
d = desplazamiento dentro de la página.
Este esquema utiliza varias tablas, entre estas se encuentran:
- SMT(tabla de mapas de segmentos): una para cada proceso. En cada entrada de la tabla se almacena la información descrita bajo segmentación pura, pero en el campo de dirección se indicará la dirección de la PMT (tabla de mapas de páginas) que describe a las diferentes páginas de cada segmento.
- PMT(tabla de mapas de páginas): una por segmento; cada entrada describe una página de un segmento; en la forma que se presentó la página pura.
- TBM(tabla de bloques de memoria): se utiliza para controlar asignación de páginas por parte del sistema operativo.
- JT(tabla de Jobs): contiene las direcciones de comienzo de cada una de las SMT de los procesos que se ejecutan en memoria. En el caso, de que un segmento sea de tamaño inferior o igual al de una página, no se necesita tener la correspondiente PMT, actuándose en igual forma que bajo segmentación pura; puede arreglarse un bit adicional (S) a cada entrada de la SMT, que indicara si el segmento esta paginado o no.
Desventajas de un Sistema con Segmentación
Por otro lado, existen varias desventajas que presenta este esquema, entre ellas se encuentran las siguientes:
- Incremento en los costos de hardware y de software para llevar a cabo la implementación, así como un mayor consumo de recursos: memoria, tiempo de CPU, etc.
- Debido a que los segmentos tienen un tamaño variable se pueden presentar problemas de fragmentación externas, en consecuencia, se debería implementar algún algoritmo de reubicación de segmentos en memoria principal.
- Dificulta el manejo de memoria virtual, ya que este tipo de memoria almacena la información en bloques de tamaños fijos, mientras que los segmentos son de tamaño variable. Esto hace necesaria la existencia de mecanismos más costosos que los existentes para paginación.
- Debido a la variación de tamaño de los segmentos, puede ser necesarios planes de reubicación a nivel de disco, si los segmentos son devueltos a dicho dispositivo; lo que conlleva a nuevos costos.
- No se puede garantizar, que, al salir un segmento de la memoria, este pueda ser traído fácilmente de nuevo, ya que será necesario encontrar nuevamente un área de memoria libre ajustada a su tamaño.
- La compartición de segmentos permite ahorrar memoria, pero requiere de mecanismos adicionales de hardware y software.
Ventajas de un Sistema con Segmentación
Algunas de las ventajas que ofrece el esquema de segmentación son:
- La segmentación es normalmente visible al programador y se proporciona como una utilidad para organizar programas y datos.
- Es posible compilar módulos separados como segmentos; el enlace entre los segmentos puede suponer hasta tanto se haga una referencia entre segmentos. Como consecuencia de esto, se hace más fácil la modificación de los mismos. Los cambios dentro de un módulo no afectan al resto de los módulos.
- Facilidad para compartir segmentos
- Es posible que los segmentos crezcan dinámicamente según las necesidades del programa en ejecución.